随着深度学习在图像、语言、广告点击率预估等各个领域不断发展,很多团队开始探索深度学习技术在业务层面的实践与应用。而在广告CTR预估方面,新模型也是层出不穷: Wide and Deep、DeepCross Network、DeepFM、xDeepFM,美团很多篇深度学习博客也做了详细的介绍。但是,当离线模型需要上线时,就会遇见各种新的问题: 离线模型性能能否满足线上要求、模型预估如何镶入到原有工程系统等等。只有准确的理解深度学习框架,才能更好地将深度学习部署到线上,从而兼容原工程系统、满足线上性能要求。
本文首先介绍下美团平台用户增长组业务场景及离线训练流程,然后主要介绍我们使用TensorFlow Serving部署WDL模型到线上的全过程,以及如何优化线上服务性能,希望能对大家有所启发。
TensorFlow 是一个开源的机器学习框架,由 Google Brain 团队开发并维护,现已成为 Apache 软件基金会的顶级项目。它主要用于构建和部署大规模机器学习模型,尤其是深度学习模型,但也支持广泛的机器学习应用。
TensorFlow 的核心概念包括:
张量(Tensor):它是 TensorFlow 中的基本数据结构,代表了多维数组。所有的数据在 TensorFlow 中都被表示为张量,包括标量、向量、矩阵和更高维度的数据结构。
计算图(Computational Graph):TensorFlow 使用计算图来描述数学运算流程。计算图是一系列的操作(Operation)连接起来的结构,其中节点表示数学运算,边表示在这些运算之间流动的数据(即张量)。
会话(Session):在旧版本的 TensorFlow 中,会话是用来执行计算图的运行环境。现在随着 Eager Execution 的引入,直接即时执行已变得更加方便,无需显式创建会话。
变量(Variable):变量用来存储需要在多次计算迭代中持续更新的值,如神经网络的权重和偏置。
优化器(Optimizer):用于训练模型时更新变量,包含了多种梯度下降算法和其他优化方法。
高级API:除了低级API外,TensorFlow 还提供了诸如 tf.keras 等高级API,简化了模型构建、训练和评估的过程。
TensorFlow 支持多种应用场景,包括但不限于计算机视觉、自然语言处理、语音识别、强化学习等。它的设计使得模型可以在单台机器上运行,也可以轻易地扩展到分布式系统中进行训练和预测。此外,TensorFlow Lite 版本还特别针对移动设备和嵌入式系统进行了优化,便于在资源有限的环境下部署机器学习模型。
在广告精排的场景下,针对每个用户,最多会有几百个广告召回,模型会根据用户特征与每一个广告相关特征,分别预估该用户对每条广告的点击率,从而进行排序。由于广告交易平台(AdExchange)对于DSP的超时时间限制,我们的排序模块平均响应时间必须控制在10ms以内,同时美团DSP需要根据预估点击率参与实时竞价,因此对模型预估性能要求比较高。
离线数据方面,我们使用Spark生成TensorFlow原生态的数据格式tfrecord,加快数据读取。
模型方面,使用经典的Wide and Deep模型,特征包括用户维度特征、场景维度特征、商品维度特征。Wide 部分有 80多特征输入,Deep部分有60多特征输入,经过Embedding输入层大约有600维度,之后是3层256等宽全连接,模型参数一共有35万参数,对应导出模型文件大小约11M。
离线训练方面,使用TensorFlow同步 + Backup Workers[6]的分布式框架,解决异步更新延迟和同步更新性能慢的问题。
在分布式ps参数分配方面,使用GreedyLoadBalancing方式,根据预估参数大小分配参数,取代Round Robin取模分配的方法,可以使各个PS负载均衡。
计算设备方面,我们发现只使用CPU而不使用GPU,训练速度会更快,这主要是因为尽管GPU计算上性能可能会提升,但是却增加了CPU与GPU之间数据传输的开销,当模型计算并不太复杂时,使用CPU效果会更好些。
同时我们使用了Estimator高级API,将数据读取、分布式训练、模型验证、TensorFlow Serving模型导出进行封装。
使用Estimator的主要好处在于:
单机训练与分布式训练可以很简单的切换,而且在使用不同设备:CPU、GPU、TPU时,无需修改过多的代码。
Estimator的框架十分清晰,便于开发者之间的交流。
初学者还可以直接使用一些已经构建好的Estimator模型:DNN模型、XGBoost模型、线性模型等。
TensorFlow Serving是一个用于机器学习模型Serving的高性能开源库,它可以将训练好的机器学习模型部署到线上,使用gRPC作为接口接受外部调用。TensorFlow Serving支持模型热更新与自动模型版本管理,具有非常灵活的特点。
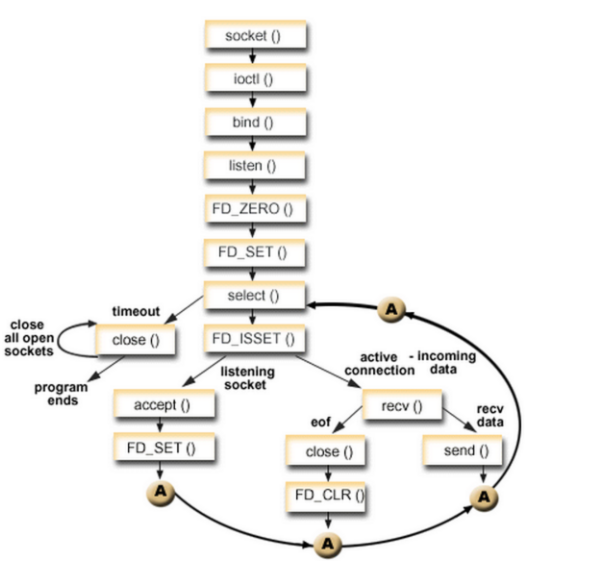
下图为TensorFlow Serving整个框架图。Client端会不断给Manager发送请求,Manager会根据版本管理策略管理模型更新,并将最新的模型计算结果返回给Client端。

图1. TensorFlow Serving架构,图片来源于TensorFlow Serving官方文档
美团内部由数据平台提供专门TensorFlow Serving通过YARN分布式地跑在集群上,其周期性地扫描HDFS路径来检查模型版本,并自动进行更新。当然,每一台本地机器都可以安装TensorFlow Serving进行试验。
在我们站外广告精排的场景下,每来一位用户时,线上请求端会把该用户和召回所得100个广告的所有信息,转化成模型输入格式,然后作为一个Batch发送给TensorFlow Serving,TensorFlow Serving接受请求后,经过计算得到CTR预估值,再返回给请求端。
部署TensorFlow Serving的第一版时,QPS大约200时,打包请求需要5ms,网络开销需要固定3ms左右,仅模型预估计算需要10ms,整个过程的TP50线大约18ms,性能完全达不到线上的要求。接下来详细介绍下我们性能优化的过程。
线上请求端优化主要是对一百个广告进行并行处理,我们使用OpenMP多线程并行处理数据,将请求时间性能从5ms降低到2ms左右。
#pragma omp parallel for
for (int i = 0; i < request->ad_feat_size(); ++i) {
tensorflow::Example example;
data_processing();
}在没有进行优化之前,模型的输入是未进行处理的原格式数据,例如,渠道特征取值可能为:'渠道1'、'渠道2' 这样的string格式,然后在模型里面做One Hot处理。
最初模型使用了大量的高阶tf.feature_column对数据进行处理, 转为One Hot和embedding格式。 使用tf.feature_column的好处是,输入时不需要对原数据做任何处理,可以通过feature_column API在模型内部对特征做很多常用的处理,例如:tf.feature_column.bucketized_column可以做分桶,tf.feature_column.crossed_column可以对类别特征做特征交叉。但特征处理的压力就放在了模型里。
为了进一步分析使用feature_column的耗时,我们使用tf.profiler工具,对整个离线训练流程耗时做了分析。在Estimator框架下使用tf.profiler是非常方便的,只需加一行代码即可。
with tf.contrib.tfprof.ProfileContext(job_dir + ‘/tmp/train_dir’) as pctx: estimator = tf.estimator.Estimator(model_fn=get_model_fn(job_dir), config=run_config, params=hparams)
下图为使用tf.profiler,网络在向前传播的耗时分布图,可以看出使用feature_column API的特征处理耗费了很大时间。

图2. 优化前profiler记录, 前向传播的耗时占总训练时间55.78%,
主要耗费在feature_column OPS对原始数据的预处理
为了解决特征在模型内做处理耗时大的问题,我们在处理离线数据时,把所有string格式的原生数据,提前做好One Hot的映射,并且把映射关系落到本地feature_index文件,进而供线上线下使用。这样就相当于把原本需要在模型端计算One Hot的过程省略掉,替代为使用词典做O(1)的查找。同时在构建模型时候,使用更多性能有保证的低阶API替代feature_column这样的高阶API。下图为性能优化后,前向传播耗时在整个训练流程的占比。可以看出,前向传播的耗时占比降低了很多。
TensorFlow采用有向数据流图来表达整个计算过程,其中Node代表着操作(OPS),数据通过Tensor的方式来表达,不同Node间有向的边表示数据流动方向,整个图就是有向的数据流图。
XLA(Accelerated Linear Algebra)是一种专门对TensorFlow中线性代数运算进行优化的编译器,当打开JIT(Just In Time)编译模式时,便会使用XLA编译器。整个编译流程如下图所示:

图4. TensorFlow计算流程
首先TensorFlow整个计算图会经过优化,图中冗余的计算会被剪掉。HLO(High Level Optimizer)会将优化后的计算图生成HLO的原始操作,XLA编译器会对HLO的原始操作进行一些优化,最后交给LLVM IR,进而根据不同的后端设备,生成不同的机器代码。
JIT的使用,有助于LLVM IR根据 HLO原始操作生成更高效的机器码;同时,对于多个可融合的HLO原始操作,会融合成一个更加高效的计算操作。但是JIT的编译是在代码运行时进行编译,这也意味着运行代码时会有一部分额外的编译开销。

图5. 网络结构、Batch Size对JIT性能影响[7]
上图显示为不同网络结构,不同Batch Size下使用JIT编译后与不使用JIT编译的耗时之比。可以看出,较大的Batch Size性能优化比较明显,层数与神经元个数变化对JIT编译优化影响不大。
在实际的应用中,具体效果会因网络结构、模型参数、硬件设备等原因而异。
经过上述一系列的性能优化,模型预估时间从开始的10ms降低到1.1ms,请求时间从5ms降到2ms。整个流程从打包发送请求到收到结果,耗时大约6ms。
通过监控发现,当模型进行更新时,会有大量的请求超时。如下图所示,每次更新都会导致有大量请求超时,对系统的影响较大。通过TensorFlow Serving日志和代码分析发现,超时问题主要源于两个方面,一方面,更新、加载模型和处理TensorFlow Serving请求的线程共用一个线程池,导致切换模型时无法处理请求;另一方面,模型加载后,计算图采用Lazy Initialization方式,导致第一次请求需要等待计算图初始化。

图7. 模型切换导致请求超时
问题一主要是因为加载和卸载模型线程池配置问题,在源代码中:
uint32 num_load_threads = 0; uint32 num_unload_threads = 0;
这两个参数默认为 0,表示不使用独立线程池,和Serving Manager在同一个线程中运行。修改成1便可以有效解决此问题。
模型加载的核心操作为RestoreOp,包括从存储读取模型文件、分配内存、查找对应的Variable等操作,其通过调用Session的run方法来执行。而默认情况下,一个进程内所有Session的运算均使用同一个线程池。所以导致模型加载过程中加载操作和处理Serving请求的运算使用同一线程池,导致Serving请求延迟。解决方法是通过配置文件设置,可构造多个线程池,模型加载时指定使用独立的线程池执行加载操作。
对于问题二,模型首次运行耗时较长的问题,采用在模型加载完成后提前进行一次Warm Up运算的方法,可以避免在请求时运算影响请求性能。这里使用Warm Up的方法是,根据导出模型时设置的Signature,拿出输入数据的类型,然后构造出假的输入数据来初始化模型。
通过上述两方面的优化,模型切换后请求延迟问题得到很好的解决。如下图所示,切换模型时毛刺由原来的84ms降低为4ms左右。

图8. 优化后模型切换后,毛刺降低
本文主要介绍了用户增长组基于Tensorflow Serving在深度学习线上预估的探索,对性能问题的定位、分析、解决;最终实现了高性能、稳定性强、支持各种深度学习模型的在线服务。
在具备完整的离线训练与在线预估框架基础之后,我们将会加快策略的快速迭代。在模型方面,我们可以快速尝试新的模型,尝试将强化学习与竞价结合;在性能方面,结合工程要求,我们会对TensorFlow的图优化、底层操作算子、操作融合等方面做进一步的探索;除此之外,TensorFlow Serving的预估功能可以用于模型分析,谷歌也基于此推出What-If-Tools来帮助模型开发者对模型深入分析。最后,我们也会结合模型分析,对数据、特征再做重新的审视。
原文链接: https://www.yukx.com/meituantech/article/details/2459.html 优科学习网基于TensorFlow Serving的深度学习在线预估