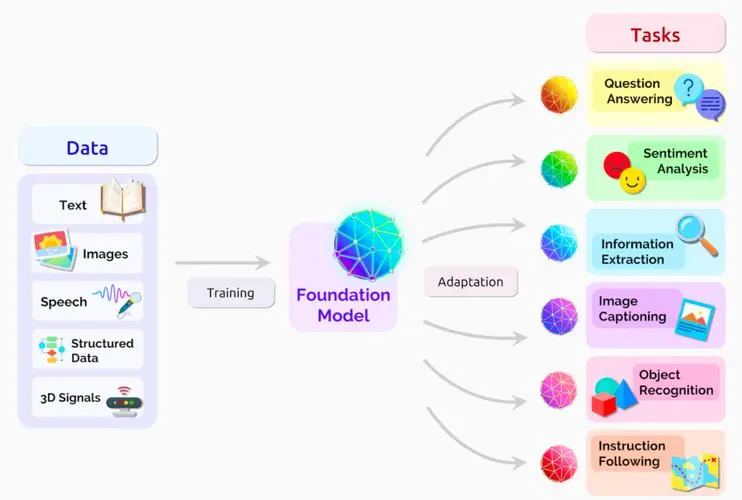
应用开源工具搭建AI大模型涉及多个步骤,以下是一个大致流程,结合上述信息中的开源工具和技术栈:
选择开源模型:
可以选用已开源的大规模预训练模型,如LLaMA、GPT-3(通过API或部分权重)、ChatGLM3等。
环境配置:
首先确保本地或者服务器有足够的硬件资源,特别是GPU或者TPU,用于模型推理和可能的微调。
安装必要的Python环境,以及依赖库,例如TensorFlow、PyTorch、Hugging Face Transformers等。
模型获取与加载:
从GitHub或其他开源平台下载模型文件,使用相关工具(如Transformers库)加载模型权重。
基础设施准备:
使用像Langchain这样的框架,可以简化构建基于AI模型的服务应用。
利用MegEngine/MegFlow这类工具,针对计算机视觉应用,搭建流式计算框架并部署模型。
模型微调与定制:
如果需要针对特定领域进行优化,可以使用开源工具和自有数据对模型进行进一步训练或微调。
应用集成与部署:
结合OpenAI Flowise、LocalAI等工具,将模型封装成API服务供其他应用调用。
使用Llama或类似的项目,部署到私有服务器或云环境中,创建对话式AI应用。
测试与优化:
在部署完成后,进行详尽的功能测试和性能优化,确保模型在实际场景下表现良好。
具体操作步骤会根据所选开源工具和目标应用场景的不同而有所差异。在搭建过程中,需要注意的是遵循版权协议,合法合规地使用开源资源,并且考虑到模型的大小和计算需求,确保相应的硬件设施能够满足运行要求。同时,持续关注安全性和隐私保护问题,特别是在处理敏感数据时。
开源社区是技术发展的一个重要部分,对于AI大模型来说,也是如此。
下面我们来尝试通过开源工具来构建AI大模型的底座,涉及到的技术包括:
Langchain
OpenAI
Flowise
LocalAI
Llama
如果你使用过ChatGPT,你应该知道它是一个基于大语言模型的应用程序,可以与人类进行多轮对话。
为了让大语言模型能够与人类友好的多轮对话,我们需要引入两个额外组件:
ConversationBufferMemory,它帮助LLM记录我们的对话过程。
ConversationChain,它帮我们管理整个绘画过程,通过调用BufferMemory中的对话信息,它可以让无状态的LLM了解我们的对话上下文。
我们可以使用下面的代码来通过Langchain实现一个简易版的ChatGPT:
from langchain.llms import OpenAI from langchain.chains import ConversationChain from langchain.memory import ConversationBufferMemory import os os.environ["OPENAI_API_KEY"] = '...' llm = OpenAI(temperature=0) mem = ConversationBufferMemory() # Here it is by default set to "AI" conversation = ConversationChain(llm=llm, verbose=True, memory=mem) conversation.predict(input="Hi there!")
Flowise官网:https://flowiseai.com/
Flowise is a low-code/no-code drag & drop tool with the aim to make it easy for people to visualize and build LLM apps.
我们可以在Windows/Mac/Linux中安装Flowise,以Linux为例,安装Flowise步骤如下:
安装NodeJS
安装Docker和Docker compose
运行下面的脚本安装和启动Flowise npm install -g flowise npx flowise start
我们可以通过http://{server}:3000 来访问Flowise,截图如下:

通过Flowise Portal,我们可以创建新的Chatflow,在打开的flow页面,我们可以通过拖拽的方式,来构建flow:

例如,我们上面提到的通过Langchain来构建简易ChatGPT应用,创建出来的flow如下截图:

我们可以通过页面右上角的对话按钮,对我们的flow进行测试:

在实际应用中,我们可以为模型增加外部记忆,在提示词中引入一些领域知识,来帮助模型提升回答质量。
这种方式的具体步骤如下:
对输入文档进行切片,生成语义向量(Embedding),存入向量数据库作为外部记忆。
根据所提的问题,检索向量数据库,获取文档中的内容片段。
把文档片段和所提的问题一并组织成提示词,提交给大语言模型,让其理解文档内容,针对问题生成恰当的答案。
为了实现这个应用,我们需要引入以下组件:
Docx File Loader,负责加载外部输入的文档。
Recursive Character Text Splitter,用来对文档内容进行断句切片。
OpenAI Embeddings,负责将断句后的内容切片映射成高维Embedding。
In-Memory Vector Store,负责将Embedding存入数据库中,供LLM作为外部记忆。
Conversational Retrieval QA Chain,负责根据问题,获得外部知识,在LLM思考生成答案后返回给用户。
使用Flowise构建上述的应用,截图如下:

我们前面做的LLM应用都依赖于OpenAI API,会有一些风险,我们可以考虑构建本地大模型。
我们可以基于LocalAI开源应用来实现这一点。
下面是搭建过程:
$ git clone https://github.com/go-skynet/LocalAI $ cd LocalAI
我们使用一个小模型进行部署。
$ wget https://gpt4all.io/models/ggml-gpt4all-j.bin -O models/ggml-gpt4all-j $ cp -rf prompt-templates/ggml-gpt4all-j.tmpl models/
然后我们可以加载models并将其封装为API服务。
$ docker-compose pull $ docker-compose up -d
接下来是获取model列表进行验证。
$ curl http://localhost:8080/v1/models
{"object":"list","data":[{"id":"ggml-gpt4all-j","object":"model"}]}这样我们可以修改Flowise,使用本地模型代替OpenAI。
我们还可以使用Llama2来构建LLM应用,这在应用许可上更加友好。
我们可以下载Llama2模型文件。
$ wget -c "https://huggingface.co/TheBloke/Llama-2-7B-chat-GGML/resolve/main/llama-2-7b-chat.ggmlv3.q4_0.bin" ./models
然后重启LocalAI,查看Llama2是否被正常部署。
$ curl -v http://localhost:8080/v1/models
{"object":"list","data":[{"id":"llama-2-7b-chat.ggmlv3.q4_0.bin","object":"model"}]}我们可以返回Flowise flow,将模型名字修改为llama-2-7b-chat.ggmlv3.q4_0.bin,这样我们就可以使用Llama2来回答我们的问题。
再进一步,我们还可以尝试使用AutoGPT或者AgentGPT来构建更加负责的LLM应用,帮助我们完成更有挑战性的事情。
原文链接: https://www.yukx.com/aigc/article/details/2455.html 优科学习网如何搭建AI大模型基础框架