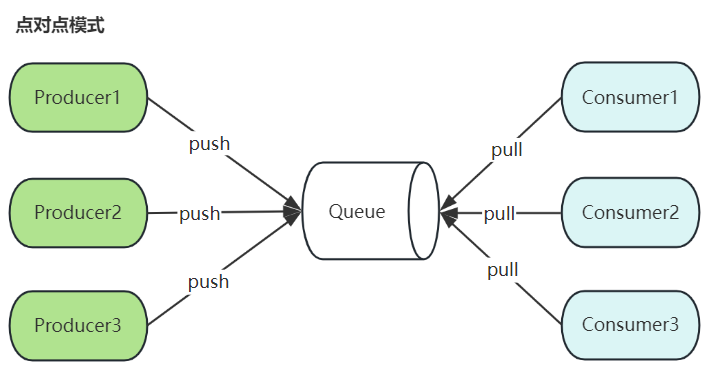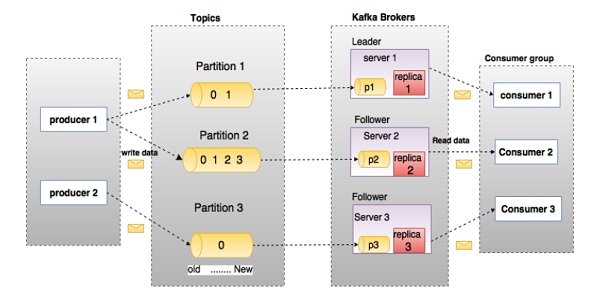
在上图中,主题配置为三个分区。 分区1具有两个偏移因子0和1.分区2具有四个偏移因子0,1,2和3.分区3具有一个偏移因子0.副本的id与承载它的服务器的id相同。
假设,如果主题的复制因子设置为3,那么Kafka将创建每个分区的3个相同的副本,并将它们放在集群中以使其可用于其所有操作。 为了平衡集群中的负载,每个代理都存储一个或多个这些分区。 多个生产者和消费者可以同时发布和检索消息。
| S.No | 组件和说明 |
|---|---|
| 1 | Topics(主题) 属于特定类别的消息流称为主题。 数据存储在主题中。 主题被拆分成分区。 对于每个主题,Kafka保存一个分区的数据。 每个这样的分区包含不可变有序序列的消息。 分区被实现为具有相等大小的一组分段文件。 |
| 2 | Partition(分区) 主题可能有许多分区,因此它可以处理任意数量的数据。 |
| 3 | Partition offset(分区偏移) 每个分区消息具有称为的唯一序列标识。 |
| 4 | Replicas of partition(分区备份) 副本只是一个分区的。 副本从不读取或写入数据。 它们用于防止数据丢失。 |
| 5 | Brokers(经纪人)
|
| 6 | Kafka Cluster(Kafka集群) Kafka有多个代理被称为Kafka集群。 可以扩展Kafka集群,无需停机。 这些集群用于管理消息数据的持久性和复制。 |
| 7 | Producers(生产者) 生产者是发送给一个或多个Kafka主题的消息的发布者。 生产者向Kafka经纪人发送数据。 每当生产者将消息发布给代理时,代理只需将消息附加到最后一个段文件。 实际上,该消息将被附加到分区。 生产者还可以向他们选择的分区发送消息。 |
| 8 | Consumers(消费者) Consumers从经纪人处读取数据。 消费者订阅一个或多个主题,并通过从代理中提取数据来使用已发布的消息。 |
| 9 | Leader(领导者) 是负责给定分区的所有读取和写入的节点。 每个分区都有一个服务器充当Leader |
| 10 | Follower(追随者) 跟随领导者指令的节点被称为Follower。 如果领导失败,一个追随者将自动成为新的领导者。 跟随者作为正常消费者,拉取消息并更新其自己的数据存储。 |
看看下面的插图。 它显示Kafka的集群图。
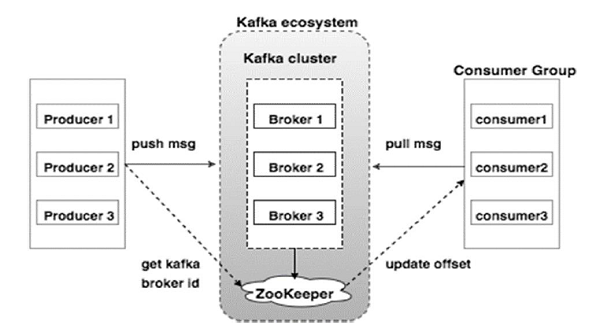
下表描述了上图中显示的每个组件。
| S.No | 组件和说明 |
|---|---|
| 1 | Broker(代理) Kafka集群通常由多个代理组成以保持负载平衡。 Kafka代理是无状态的,所以他们使用ZooKeeper来维护它们的集群状态。 一个Kafka代理实例可以每秒处理数十万次读取和写入,每个Broker可以处理TB的消息,而没有性能影响。 Kafka经纪人领导选举可以由ZooKeeper完成。 |
| 2 | ZooKeeper ZooKeeper用于管理和协调Kafka代理。 ZooKeeper服务主要用于通知生产者和消费者Kafka系统中存在任何新代理或Kafka系统中代理失败。 根据Zookeeper接收到关于代理的存在或失败的通知,然后产品和消费者采取决定并开始与某些其他代理协调他们的任务。 |
| 3 | Producers(生产者) 生产者将数据推送给经纪人。 当新代理启动时,所有生产者搜索它并自动向该新代理发送消息。 Kafka生产者不等待来自代理的确认,并且发送消息的速度与代理可以处理的一样快。 |
| 4 | Consumers(消费者) 因为Kafka代理是无状态的,这意味着消费者必须通过使用分区偏移来维护已经消耗了多少消息。 如果消费者确认特定的消息偏移,则意味着消费者已经消费了所有先前的消息。 消费者向代理发出异步拉取请求,以具有准备好消耗的字节缓冲区。 消费者可以简单地通过提供偏移值来快退或跳到分区中的任何点。 消费者偏移值由ZooKeeper通知。 |
原文链接: https://www.yukx.com/kafkamq/article/details/2099.html 优科学习网Kafka集群架构